안녕하세요 먼지입니다.
회사에서 AI Agent 프로젝트를 하다보니 집에서도 llm 환경을 구축해보면 좋지 않을까라는 생각이 들었습니다. 모든 일을 경험할 수 있는 건 아니다보니 집에서 개인 프로젝트로 경험해보고 싶은 것들이 생기더라고요. 성능 좋은 gpt, claude 모델은 아니더라도 간단한 프로젝트를 진행할 수 있도록 설치를 진행해보았습니다.
로컬 환경의 본래의 가장 큰 목적은 "보안"이지만, 저 같은 일반 개발자들에게는 아무래도 "무료" 인 점이지 않을까 싶습니다.
연습을 하고 싶은데 과금이 얼마나 나올지도 몰라 불안한 점을 해결할 수 있을 것 같습니다.
제가 처음으로 설치한 모델은 "Ollama" 모델입니다. 이유는 메타의 오픈소스이고, 가장 유명한 로컬모델이기 때문에 성능이 궁금했습니다. 지금부터 ollama 설치 과정을 하나하나 공유 드려보겠습니다.
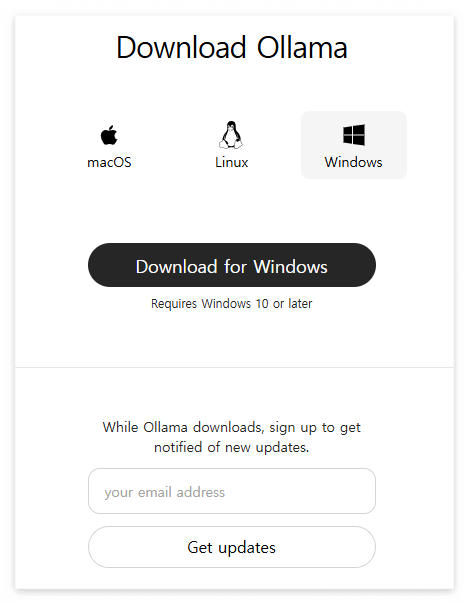
1. ollama 다운로드
올라마 홈페이지에 가면 다운로드 페이지가 있습니다. 위 사진처럼 운영체제에 맞는 ollama를 다운로드 해주시면 됩니다!
홈페이지 : https://ollama.com/
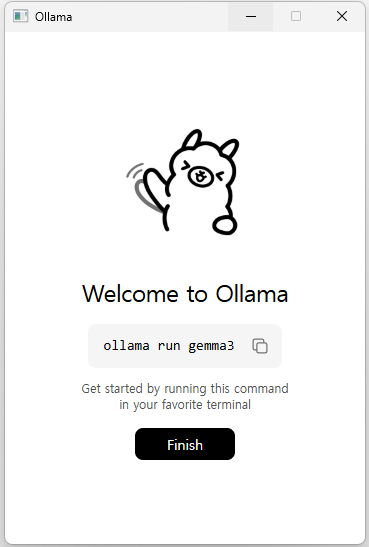
설치가 완료되면 위 사진처럼 "Welcome to Ollama"가 뜹니다! 설치가 제대로 되었는지 확인하고 싶으시면 명령어 "ollama list"를 쳐보시면 됩니다. 설치 전 ollama list 명령어를 치면 에러가 발생합니다.

설치전엔 오류가 떴었지만 설치 완료 이후 Name, ID, SIZE, MODIFIED 가 생긴 걸 볼 수 있습니다.

2. 로컬 모델 다운로드
이제 ollama에서 내가 사용할 모델을 다운로드 받아야 합니다. 첫 설치라 모델 다운로드인지도 모르고 Welcome to Ollama 에 나온 "ollama run gemma3" 를 실행했었네요. 퍼센테이지와 GB 를 보고 모델 설치구나 알았습니다..!
결과는 에러 발생이었습니다. "Error: model requires more system memory than is available" system메모리가 부족하다는 에러였습니다. 최근 노트북을 살때 분명 램 16GB로 샀었는데 5.6GB 때문에 에러인 걸 보고 메모리 사양을 먼저 체크해야겠다고 생각했습니다.
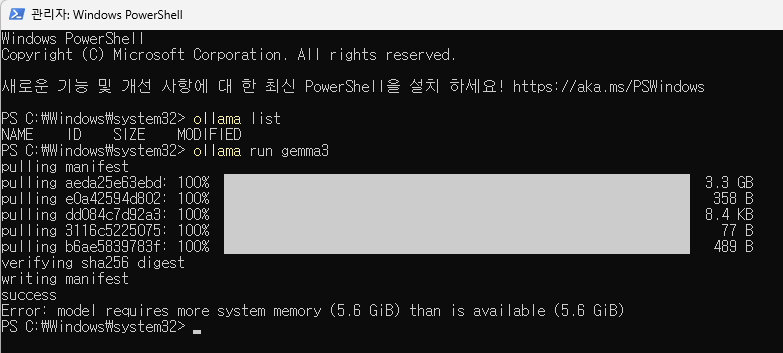
3. (로컬 모델 설치 전) 내 컴퓨터(노트북) 성능 알아보기
첫 설치라 내 컴퓨터 성능에 맞는 어떤 llm 모델을 설치해야 할지 잘 모르겠더라고요. 홈페이지에 가서 보시면 아시겠지만 deepseek 부터 시작해서 모델이 정말 많습니다. 그래서 gpt에 검색해봤더니 어디서 확인해야 하는지까지 잘 알려주네요.
작업관리자 -> 성능 탭에 가면 자신의 컴퓨터 메모리 성능을 쉽게 확인할 수 있습니다.

성능 확인 결과 제 노트북의 사용가능 램 메모리가 4.9GB 여서 error가 발생했었습니다. 램 자체는 16GB여서 인터넷 창을 끄고 설치를 진행했습니다. 또한 VRAM을 확인해보니 8.8GB인 것을 확인했습니다.
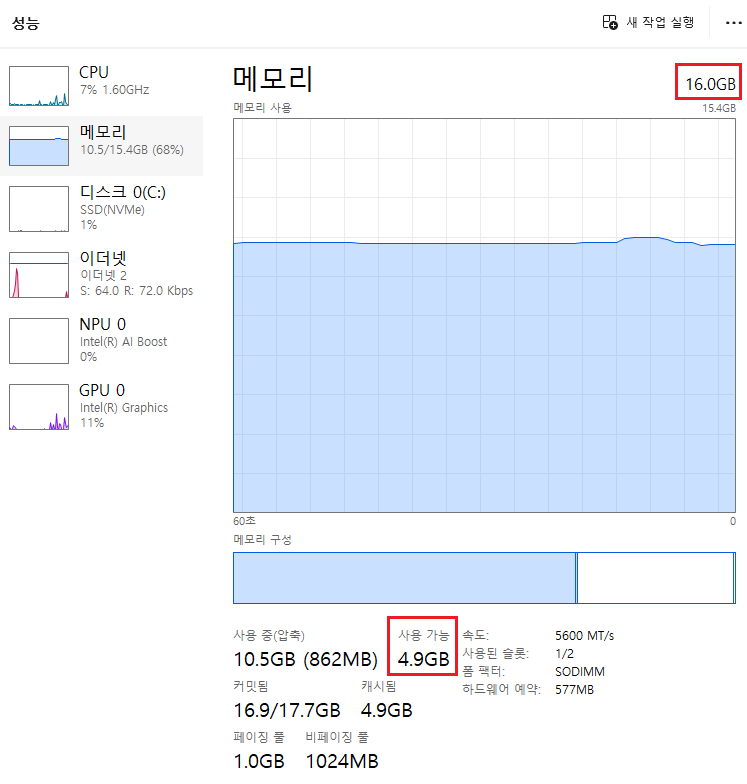

이렇게 알아보고 나니 선택이 쉬워졌습니다. 제가 선택할 수 있는 모델이 애초에 거의 없었습니다..ㅎㅎ lastest가 써져있는 llama3.1:8b 모델을 선택했습니다. 터미널 창에 "ollama run llama3:8b" 명령어를 통해 설치를 진행했습니다.
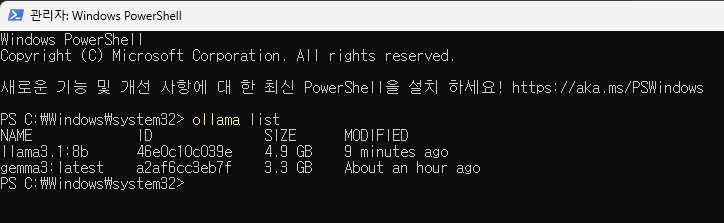
llama3.1:8b 모델이 잘 설치된 것을 볼 수 있습니다.
터미널에서 라마 모델을 작동시켜봤습니다.
"Do you know about AI Agent?" 라는 질문에 대해 꽤나 자세하게 답변해주는 것을 볼 수 있습니다.

4. API로 ollama 활용하기
실제 프로젝트를 하기 위해선 API로 llm 모델을 가져와야 합니다. 그래서 어떻게 API를 호출하는지 조사를 해봤습니다. 아래는 공식홈페이지 API 관련 문서입니다. 로컬 호스트 11434 포트를 사용하는 것으로 보입니다.
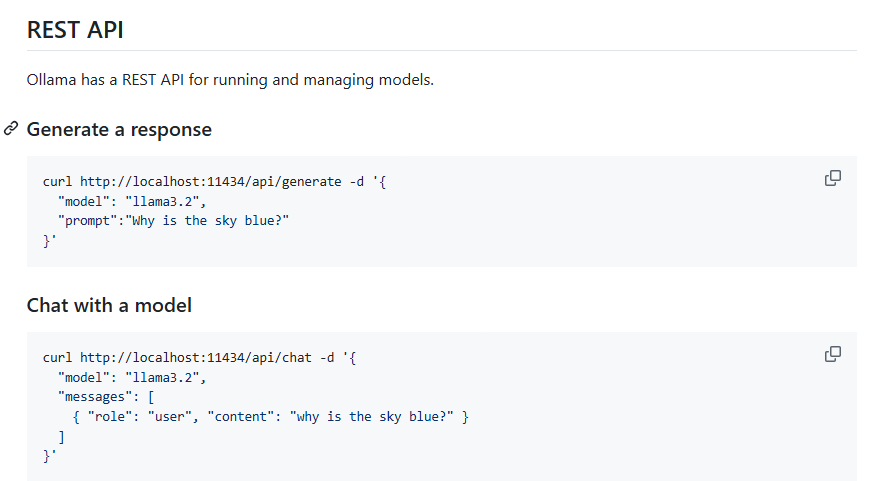
https://github.com/ollama/ollama
GitHub - ollama/ollama: Get up and running with Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1 and other large langua
Get up and running with Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1 and other large language models. - ollama/ollama
github.com
아래는 파이썬으로 ollama API로 불러오는 코드입니다. 저의 경우 모델명을 "llama3.1"까지만 적어 api를 작동시키는데 꽤나 오랜 시간을 썼네요. 설치한 모델명을 정확히 적어주셔야 합니다.
import requests
url = "http://localhost:11434/api/chat"
payload = {
"model": "llama3.1:8b",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "AI Agent에 대해 설명해주세요"}
],
"stream": False
}
response = requests.post(url, json=payload)
print(response.json()["message"]["content"])
터미널에서와 같이 "AI Agent에 대해 설명해주세요" 라는 질문을 던졌고 답변 결과는 아래와 같습니다.
답변 시간은 1분 30초, 영어로 질문했을 땐 잘 대답했지만 한국어 질문에 대해 AI Agent 대신 AI에 대해 설명하고 있습니다. 한국어 성능은 떨어지는 것으로 보입니다.

5. 느낀점
지금까지 ollama 로컬 모델 설치를 진행해보았습니다. 뭐든 셋팅이 참 어려운 것 같습니다. 처음 설치할 땐 모든 게 낯설었지만 한번 해보고 나니 할만한 것 같습니다.
해보고 느낀점은 "로컬 설치이다 보니 유료모델보다 속도, 성능이 떨어진다는 점"입니다.
사용하려는 데이터 크기에 따라 달라지겠지만, 한국어 모델 특화 모델을 다운로드에 사용하거나 연습을 충분히 한 뒤 유료모델로 넘어가는 방법을 고민해야 할 것 같습니다.
읽어주셔서 감사합니다 :)
'AI agent' 카테고리의 다른 글
| 정형데이터에서 VectorDB를 사용하는 이유 (5) | 2025.08.03 |
|---|---|
| SelfQuery-Retriever 사용 경험 정리(feat.걸려라 필터링!) (2) | 2025.07.12 |