* 공부한 것을 정리한 글이므로 틀린 내용이 있을 수 있습니다.
* 더 좋은 방법 또는 틀린부분이 발견될 시 계속 수정하며 업데이트 할 예정입니다.
안녕하세요
오늘은 전처리 파이프라인에 대해 정리해보려 합니다.
정제되지 않은 데이터 파일을 받았을 경우 전처리를 해줘야 하는데 이런 파일들이 계속 들어오게 된다면
매번 전처리하기 성가시고 힘들게 됩니다.
그래서 모든 전처리 과정을 하나의 파이프라인으로 만들어 데이터를 이 파이프라인에 넣어주게 되면
모델 돌리기에 적합한 형태의 형식의 데이터로 나올 수 있게 만들어 줄 수 있습니다.
이번에 다뤄볼 데이터는 seaborn에 있는 'diamond' 데이터 셋입니다.
# 데이터셋
df = sns.load_dataset('diamonds')
df
Nan값은 없었고 데이터 타입을 살펴보니 숫자는 int, float형식, object의 경우 category 형 타입이었습니다.


이 데이터를 파이프라인을 통해 모델에 넣을 수 있는 데이터가 나올 수 있도록 간단하게 구현해보겠습니다.
1. numeric 데이터
숫자형 데이터 전처리에 여러가지가 있지만 모듈로 구현된 기본적인 전처리 Nan값 채우기, 스케일링을 진행해보겠습니다.
(Nan값이 없지만 있다고 가정하겠습니다)

숫자형의 경우 위의 7개의 컬럼이고 이 컬럼들만 처리해주는 파이프라인을 만들어보겠습니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# 숫자형인 컬럼명
numeric_col = list(df.select_dtypes(exclude='category').columns)
numeric_col
# 평균값으로 Nan값 채워주기
num_imputer = SimpleImputer(strategy='mean')
# 스케일링
scaler = StandardScaler()
# 파이프라인 구축
numeric_pipeline = Pipeline(
steps=[
('imputer', num_imputer),
('scaler', scaler)
])
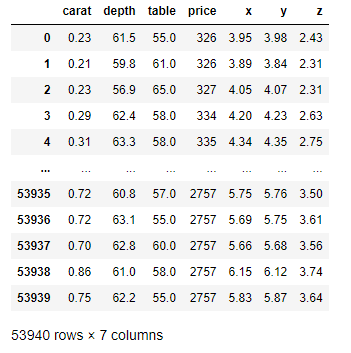
파이프라인에 fit_transform 을 통해 바꿔준 모습입니다.
파이프라인을 통과하면 데이터가 array형식으로 나오기 때문에 컬럼명을 지정해줘서 보기 좋게 데이터프레임 형식으로 만들어보았습니다.
num_data_piped = numeric_pipeline.fit_transform(df.select_dtypes(exclude='category'))
pd.DataFrame(num_data_piped, columns=numeric_col)

2. category 데이터
마찬가지로 여러가지 전처리가 있지만 모듈로 구현된 기본적인 전처리 Nan값 채우기, 원핫인코딩을 진행해보겠습니다.
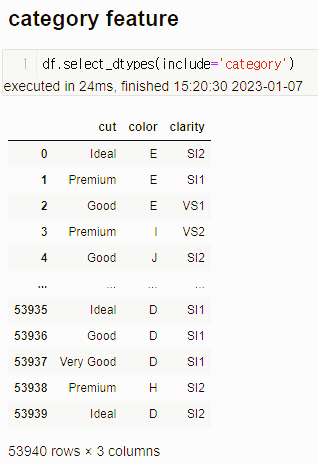
숫자형 파이프라인과 거의 비슷한 형식입니다.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
category_col = list(df.select_dtypes(include='category').columns)
# category_col: 비어있는 값을 'missing'으로 채우기
category_imputer = SimpleImputer(strategy='constant', fill_value='missing')
# Onehotencoder
onehot_encoder = OneHotEncoder(sparse=False)
# 파이프라인 구축
category_pipeline = Pipeline(
steps=[
('imputer', category_imputer),
('onehot', onehot_encoder),
])
파이프라인에 fit_transform 을 통해 바꿔준 모습입니다.
파이프라인에 원핫 인코딩이 있기 때문에 새로운 컬럼이름을 지정해 줬어야 하는데 이 컬럼이름을 도출하는 데에서 애를 좀 먹었습니다ㅜ
그냥 encoder 객체에서는 encoder.get_feature_out(컬럼명) 으로 해주면 컬럼이름이 나오지만
pipeline객체에서는 pipeline[1].get_feature_out(컬럼명)으로 해줘야 컬럼명이 반환됩니다.
(파이프라인 내에 2번째에 onehot 인코딩이 들어있기 때문 )
# fit_transform을 통한 데이터 전처리
category_data_piped = category_pipeline.fit_transform(df.select_dtypes(include='category'))
# 파이프라인 적용이후 컬럼 이름
category_col = list(df.select_dtypes(include='category').columns)
category_col_piped = category_pipeline[1].get_feature_names_out(category_col)
# 파이프라인 이후 데이터(array형 -> 데이터프레임)
pd.DataFrame(category_data_piped, columns=category_col_piped)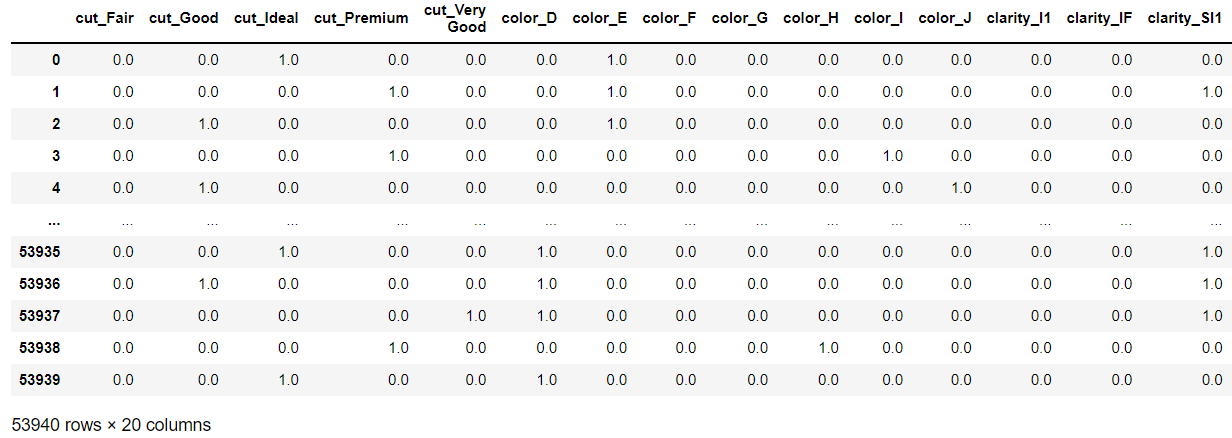
3. numeric pipeline + category pipeline 합치기
이 두 파이프라인을 하나로 합쳐주면 숫자형, 카테고리형 전처리가 한번에 진행될 수 있습니다.
이럴때 sklearn모듈의 ColumnTransformer 함수를 사용합니다.
ColumnTransformer( transform=('이름1', 파이프라인, 컬럼리스트)) 형식으로 넣어주면 됩니다.
마지막으로 전체 코드를 통해 보여드리도록 하겠습니다.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# -----------------------숫자형-------------------------------
numeric_col = list(df.select_dtypes(exclude='category').columns)
num_imputer = SimpleImputer(strategy='mean')
scaler = StandardScaler()
# 숫자형 데이터 파이프라인 구축
numeric_pipeline = Pipeline(
steps=[
('imputer', num_imputer),
('scaler', scaler)
])
# -----------------------카테고리형-------------------------------
# category_col
category_col = list(df.select_dtypes(include='category').columns)
category_imputer = SimpleImputer(strategy='constant', fill_value='Nan')
# Onehotencoder
onehot_encoder = OneHotEncoder()
# 카테고리형 파이프라인 구축
category_pipeline = Pipeline(
steps=[
('imputer', category_imputer ),
('onehot', onehot_encoder),
])
# -----------------------합치기-------------------------------
# numeric & category 파이프라인 합치기
preprocess = ColumnTransformer(
transformers=[
('numeric', numeric_pipeline, numeric_col),
('category', category_pipeline, category_col)
])
마지막은 array 형식 반환값으로 보여드리겠습니다. 마찬가지로 fit_transform 함수를 사용하여 반환값을 얻을 수 있습니다.
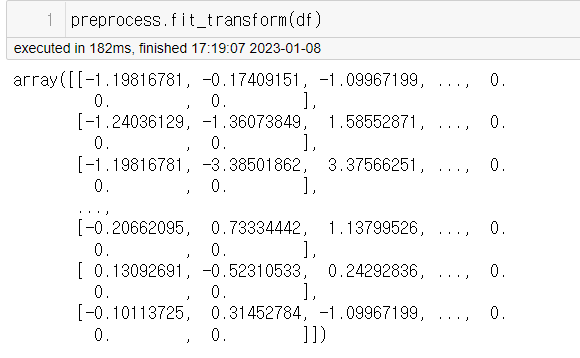
이번엔 sklearn모듈을 사용하여 전처리 파이프라인을 만들어 보았습니다.
정리하는 부분에서 전처리함수 SimpleImputer, OnehotEncoder, LabelEncoder 등등 사용법을 잘 알아야 겠다고 느꼈습니다. 추후 관련 내용을 정리해서 포스팅 해보도록 하겠습니다.
감사합니다!
참조:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
'데이터분석_ > 데이터 전처리' 카테고리의 다른 글
| [pandas] grouped 객체 for문에 사용하기 (4) | 2025.08.17 |
|---|---|
| [Pandas] 년,월,일 따로 있는 데이터 읽기 : parse_dates, date_parser, index_col (0) | 2023.01.08 |
| [전처리] 시계열 데이터에서 train, validation, test 나누기 (0) | 2023.01.04 |
| [Pandas] 시간데이터 전처리: datetime타입 형식변환 & 시간 차이 구하기 (0) | 2023.01.02 |