오늘은 풀었던 SQL 쿼리문제를 정리해보려 합니다.
가끔 기본문제 같은데 헷갈리는 문제들이 있어 정리를 꾸준히 해놔야겠다고 생각이 들었습니다.
기본문제의 경우 ChatGpt로 풀고 있는데 몰랐던 부분들을 바로바로 질문할 수 있어서 좋은 것 같습니다.
Q. 각 직원의 이름과 그 직원이 속한 전체 부서의 평균 급여를 함께 출력하라.
데이터는 아래와 같습니다.
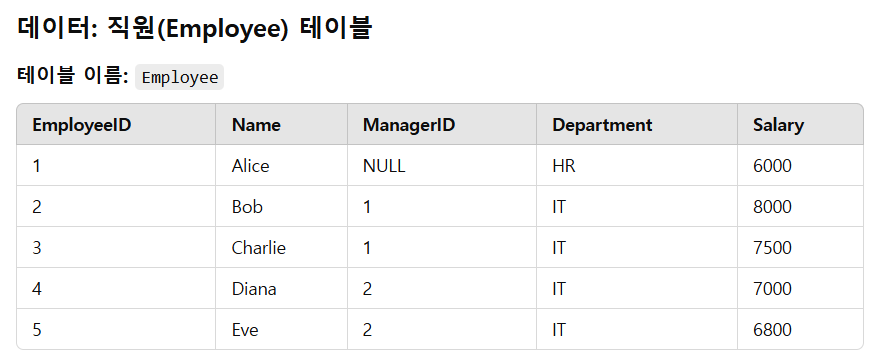
처음 접근.
1. 평균 급여가 필요하니 group by를 사용해야 하는데.
2. Department를 기준으로 group by 하게 되면 각각의 employeeID를 출력할 수가 없음.
3. 그래서 group by로 department 컬럼 뿐만 아니라 employeeID, Name 까지 해서 출력해 보았습니다.
# 처음 시도
SELECT
Name,
Department,
AVG(Salary)
FROM Employee
GROUP BY EmployeeID, Name, Department;
시도 결과
Name을 출력하려고 group by에 Name컬럼을 넣었더니 부서별 평균급여가 적용되지 않더라고요.
원래 개인의 연봉이 출력되었습니다. 아마 1개뿐인 Name으로 먼저 그룹화가 진행되니 그대로 출력된 것 같습니다.

Solution1. SELF JOIN
셀프조인 방법이 가장 먼저 Chatgpt에서 추천해주는 솔루션이었습니다.
# Soultion1: 셀프조인
SELECT
e.Name AS EmployeeName,
e.Department,
AVG(d.Salary) AS DepartmentAvgSalary
FROM Employee e
JOIN Employee d ON e.Department = d.Department
GROUP BY e.EmployeeID, e.Name, e.Department;
근데 머릿속으로 아무리 이해해보려해도 deparment행으로 조인되었을때의 그래프가 안그려지더라고요.
종이에 직접 두개의 테이블을 합쳐보기도 하고 했지만..결국 gpt에게 도움을 받았습니다.
프롬프트:
" e.Department = d.Department 위 조건으로 셀프조인했을때 나오는 모든 행이 포함된 테이블을 보여줘."
결과:

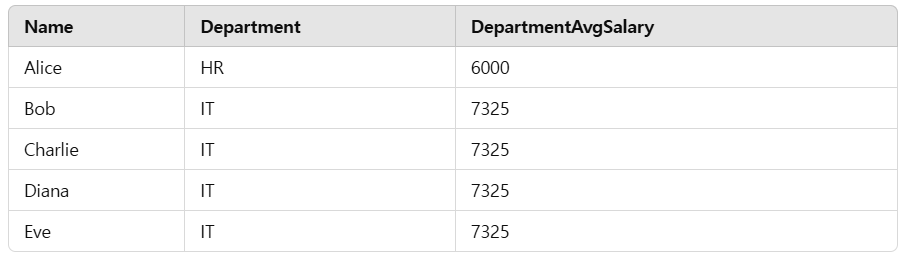
보시는것과 같이 IT 부서에 속한 모든 데이터가 조인되는 걸 볼 수 있었습니다.
Salary_e는 한사람의 급여만 나오게 되고, Salary_d의 경우 모든 IT 직원의 연봉이 출력되었습니다.
눈으로 보니 확실히 이해가 되었습니다.
Solution2. Sub-query
# 서브쿼리
SELECT
Name AS EmployeeName,
Department,
(SELECT AVG(Salary)
FROM Employee AS sub
WHERE sub.Department = e.Department) AS DepartmentAvgSalary
FROM Employee e;
employee라는 테이블에서, 현재 해당되는 department들을 가져와 평균을 구하는 쿼리였습니다.
서브쿼리가 저에겐 더 직관적이라고 생각했습니다.
Solution3. 윈도우 함수
# 윈도우 함수 사용
SELECT
Name AS EmployeeName,
Department,
AVG(Salary) OVER(PARTITION BY Department) AS DepartmentAvgSalary
FROM Employee;
GROUP BY가 그룹화된 데이터로 축소하는 반면, PARTITION BY의 경우 원본 데이터의 모든 행을 유지한다는 차이점을 가지고있다고 합니다. 따라서 각 행에 대해 그룹별 통계나 순위를 추가할 때 유용하다 하네요.
확실히 서브쿼리보다도 직관적이고 쉬운 것 같습니다.
하지만 언제 그룹바이를 쓸지 윈도우 함수를 쓸지는 아직 경험이 더 필요할 것 같습니다.
이번 포스팅에선 항상 걸렸었던 쿼리문제에 대해 정리해봤는데요.
도움이 되셨으면 좋겠습니다. 감사합니다 :)
'SQL' 카테고리의 다른 글
| [HackerRank] Occupations 직업별 피벗 테이블 만들기 (0) | 2025.03.19 |
|---|---|
| [HackerRank] The PADS 안됐던 이유 정리 (0) | 2025.03.14 |
| [HackerRank SQL] Draw The Triangle 별 삼각형 그리 (0) | 2025.03.06 |
| SQL 회원가입 후 로그인까지 소요된 평균일 수 구하기 (3) | 2025.02.04 |