안녕하세요. 오늘은 리텐션 기본문제를 정리해보려고 합니다.
코딩테스트 사이트 문제만 풀어보다가 직접 리텐션 문제를 풀어보니 꽤나 낯설더라고요.
아래는 문제와 샘플 데이터 입니다.
Q. signup 후 login까지 소요된 평균일 수를 계산하시오.
데이터 테이블: user_activity
| usser_id | activity_date | action |
| 1 | 2023-01-01 | signup |
| 1 | 2023-01-02 | login |
| 1 | 2023-01-05 | login |
| 1 | 2023-01-07 | purchase |
| 2 | 2023-01-01 | signup |
| 2 | 2023-01-04 | login |
| 2 | 2023-01-06 | login |
처음 시도
접근: action = 'signup' , action='login' 날짜를 뽑아 DATEDIFF함수에 넣어야지
근데 action에 따른 날짜를 어떻게 뽑지?
하나의 테이블에 signup 날짜와 login 날짜를 한꺼번에 추출해야 하지만 방법을 잘 몰랐습니다.
아래 2가지 방법으로 정리해보겠습니다.
Solution1. user_id를 기준으로 self join
SELECT AVG(DATEDIFF(login_date,signup_date)) AS avg_days_to_login
FROM (
SELECT ua1.user_id,
MIN(ua1.activity_date) AS signup_date,
MIN(ua2.activity_date) AS login_date
FROM user_activity ua1
JOIN user_activity ua2
WHERE
ua1.activity = 'signup'
ua2.activity = 'login'
GROUP BY ua1.user_id
) sub ;
근데 위와 같이 쿼리를 작성하면 그 많은 로그데이터에서 문제가 생길 것 같습니다.
user_id 1의 데이터 값이 3개여서 3*3 = 9행이 self-join으로 새로 생겼지만
로그가 많고 컬럼개수가 많으면 과부하가 걸릴 것 같다는 생각이 들었습니다.
self join 결과값이 궁금하시면 이전 포스팅을 참고해 주세요.
SQL 직원이 속한 전체 부서의 평균 급여 출력하기
오늘은 풀었던 SQL 쿼리문제를 정리해보려 합니다.가끔 기본문제 같은데 헷갈리는 문제들이 있어 정리를 꾸준히 해놔야겠다고 생각이 들었습니다.기본문제의 경우 ChatGpt로 풀고 있는데 몰랐던
sequence-data.tistory.com
그래서 다른 방법을 찾아봤습니다.
Solution2. CTE 사용
WITH signup_dates AS (
SELECT user_id, activity_date AS signup_date
FROM user_activity
WHERE action = 'signup'
),
first_login_dates AS (
SELECT user_id, MIN(activity_date) AS first_login_date
FROM user_activity
WHERE action = 'login'
GROUP BY user_id
)
SELECT AVG(DATEDIFF(first_login_date, signup_date)) AS avg_days_to_login
FROM signup_dates
JOIN first_login_dates USING (user_id);
(1) signup 날짜를 구하고
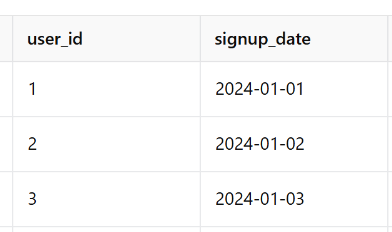
(2) 처음 로그인 활동날짜(firsrt_login_dates)를 구해서

(3) user_id 기준으로 join합니다.
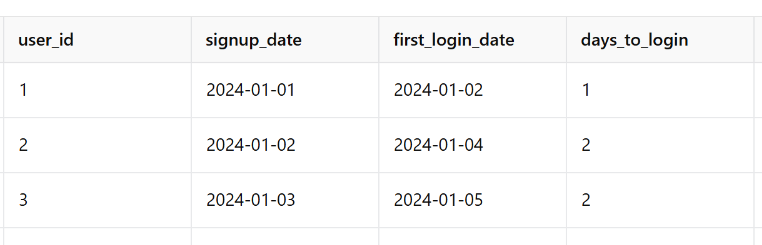
개인적으로 셀프조인보다 훨씬 이해도 잘되고 직관적인 것 같습니다.
최적화를 위해 GROUP BY 대신 ROW_NUMBER() 함수를 쓰기도 하는데 이 부분은 나중에 정리해보겠습니다.
그리고 CHATGPT가 유료버젼임에도 거짓으로 알려주는 경우가 꽤 있네요;
LAG함수에 대해 포스팅하다가 지우고 다시 썼습니다.

정신차리고 gpt를 이용해야겠습니다..
도움이 되셨으면 좋겠습니다. 감사합니다.
'SQL' 카테고리의 다른 글
| [HackerRank] Occupations 직업별 피벗 테이블 만들기 (0) | 2025.03.19 |
|---|---|
| [HackerRank] The PADS 안됐던 이유 정리 (0) | 2025.03.14 |
| [HackerRank SQL] Draw The Triangle 별 삼각형 그리 (0) | 2025.03.06 |
| SQL 직원이 속한 전체 부서의 평균 급여 출력하기 (0) | 2025.01.24 |