시계열 평가지표에 대해 정리해 보려 합니다. 회귀분석의 평가지표를 사용하며
분류문제에서 상황에 따라 필요한 평가지표가 있듯이 상황에 따른 평가지표가 존재합니다.
각 평가지표들이 왜 나오게 되었는지와 특징들을 간략하게 한번 정리해보려 합니다.
1. SSE (sum of squared errors)
: N개의 데이터의 (실제값- 예측값)의 제곱값의 합
가장 기본적인 실제값과 예측값의 차이값의 제곱의 합입니다.
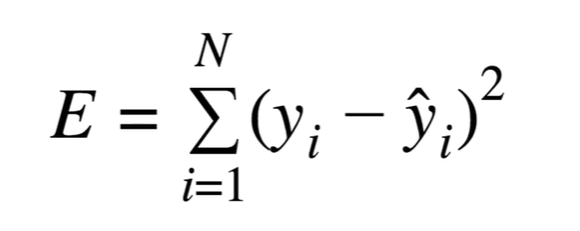
2. MSE (Mean Squared Error)
- MSE는 1번의 SSE값을 N(데이터수)으로 나눠준 값입니다.
- 예를 들어 100개의 데이터를 예측한 결과와 1000개의 데이터를 예측한 결과를 비교할 경우 단순합인 SSE를 쓰게 되면 형평성이 맞지 않게 됩니다. 이런 문제를 해결하기 위해 데이터 개수로 나눠주어 기준을 맞춰준 값이라고 합니다.
- 오차제곱 기댓값의 추정치로 사용한다고 합니다.
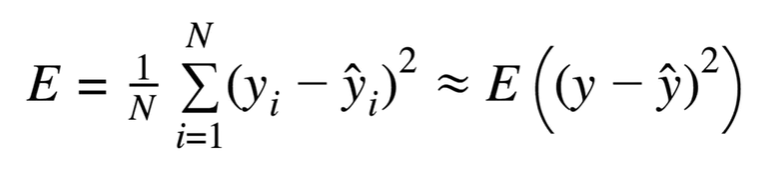
3. RMSE (Root Mean Squared Error)
- RMSE 는 SSE,MSE와 다르게 오차를 직관적으로 표현한 지표라고 합니다.
- 예를 들어 "주가 예측오차가 RMSE 1000원 입니다" 가 "주가 오차가 MSE 1000000(1000^2)원입니다" 보다 훨씬 직관적인 느낌입니다.
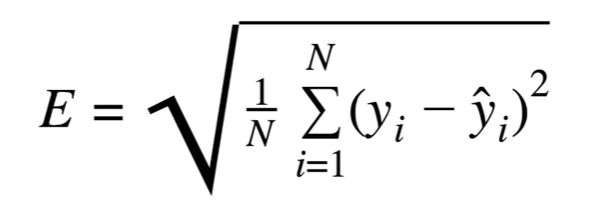
4. MAE (Mean Absoulte Error)
- 왜 제곱값을 쓰지? 절대값을 쓰면 되잖아 에서 출발한 평가지표입니다.
- Laplace-distributed error에 최적화된 평가지표라고 합니다.
- 절대값이기 때문에 제곱을 사용하는 평가지표보다 이상치에 덜 민감한 특징이 있다고 하네요!
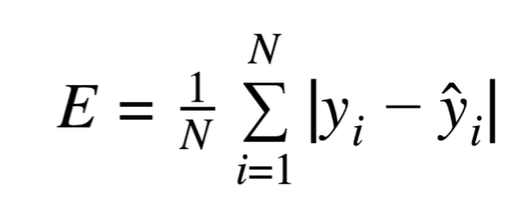
5.R^2 (설명력)
- 오차는 아니지만 예측의 성과를 나타내는 지표입니다.
- R^2 =1 : perfect 예측(MSE가 0이란 뜻이므로!)
- R^2 =0 : 가장 망한 예측

6. MAPE ( Mean Absolute Percentage Error)
- 예측결과에 있어 10000원을 10010원으로 예측한 결과와 100원을 110원으로 예측한 결과는 하늘과 땅 차이지만 단순 실제값- 예측값은 10 으로 같게되는 문제( scale-invariant error)가 생기게 됩니다.
- 이러한 에러의 비율을 맞춰주기 위해 에러비율에 절대값을 취해준 방식입니다.
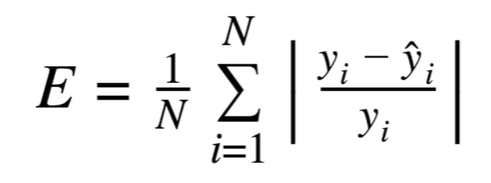
7. sMAPE ( Symmetric MAPE)
- 위의 MAPE의 방식을 사용했을 경우 100$인 주가를 110$로 예측한결과 vs 110$인 주가를 100$로 예측한 결과가 다른 문제가 생길 수 있습니다.
- 분모에 절댓값 y를 바꿔줌으로써 대칭적이지 않은 점을 보완한 방식입니다.
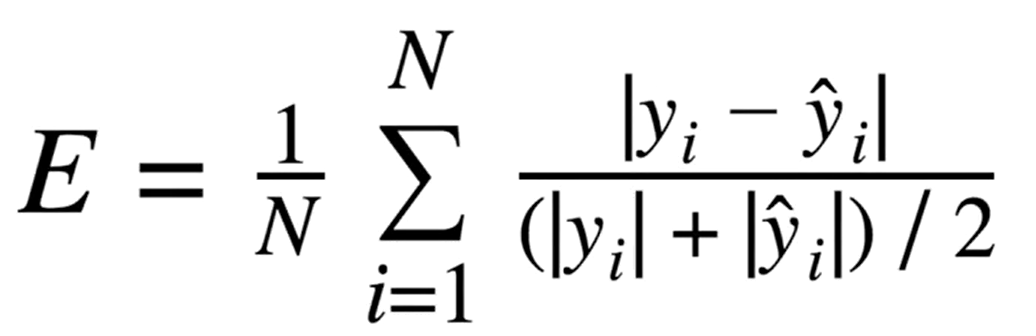
* MAPE, sMAPE의 경우 분모가 0일 경우 E가 무한대가 될 수 있는 점을 조심해야함
지금까지 시계열(회귀) 평가지표들을 공부하면서 정리해 보았습니다. 이론적인 부분도 중요하지만 직접 필요한 경우에 찾아써봐야 감이 더 잘 올 것 같은 생각이 드네요. 지금까지 평가지표 정리였습니다. 감사합니다!
참고:
lazy programmer 의 Time-series강의를 보고 정리하였습니다.
'데이터분석' 카테고리의 다른 글
| [pandas] 데이터프레임 날짜 인덱스 늘리기(reindex) (0) | 2023.03.16 |
|---|---|
| [Pandas] 데이터 음수값 없애기 (0) | 2023.03.14 |
| [시계열 시각화] plotly를 통한 시계열 시각화 (0) | 2022.12.29 |
| [시계열 시각화] seaborn으로 시계열데이터 그려보기 (0) | 2022.12.28 |