시계열 데이터 분석을 하다 보니 여러 종류의 데이터가 필요했습니다.
어떨때는 계절성이 있는 데이터를 분석하고 싶기도 하고 때로는 다변량 시계열 데이터가 분석하고 싶기도 한데 할때마다 검색해서 다운받기가 귀찮더라고요
이를 위해 darts라는 시계열 모듈을 사용해보려 합니다!
darts는 시계열 데이터 분석을 위한 모듈로 여러가지 함수와 informer를 비롯한 최신 알고리즘까지 구현이 되어있습니다. darts 모듈 dataset엔 20가지 정도의 시계열 데이터가 있는데 10가지 정도의 데이터를 살펴보도록 하겠습니다.

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn-whitegrid')1. 단변량 시계열
(1) Airpassengers
누구나 아는 대표적인 비행기 탑승객 시계열 데이터입니다. 월단 데이터이고 multiplicative 시계열 형태를 띄고 있습니다.
# 데이터 가져오기
from darts.datasets import AirPassengersDataset
display("Air Passanger Dataset",AirPassengersDataset().load().pd_dataframe())
# 시각화
df_air = AirPassengersDataset().load().pd_dataframe()
df_air.plot(figsize=(10,5), title='Airpassenger')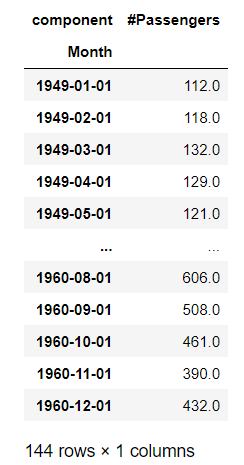

(2) Ausbeer
1956년부터 2008년 3개월 마다 오스트레일리아 맥주 판매량입니다.
추세가 있고 계절성이 보이는 데이터입니다.
# 데이터
from darts.datasets import AusBeerDataset
df_beer = AusBeerDataset().load().pd_dataframe()
df_beer
# 시각화
df_beer.plot(figsize=(10,5), title='Ausbeer')

(3) HeartRate
1800개의 일정한 간격으로 측정한 심장박동수 데이터입니다. 15분동안 0.5초 간격으로 측정했다고 합니다.
(The series contains 1800 evenly-spaced measurements of instantaneous heart rate from a single subject. The measurements (in units of beats per minute) occur at 0.5 second intervals, so that the length of each series is exactly 15 minutes.)


(4) Sunspot Dataset
# 데이터셋
from darts.datasets import SunspotsDataset
df_sun = SunspotsDataset().load().pd_dataframe()
df_sun
# 시각화
df_sun.plot(figsize=(10,5),title='SunSpots')

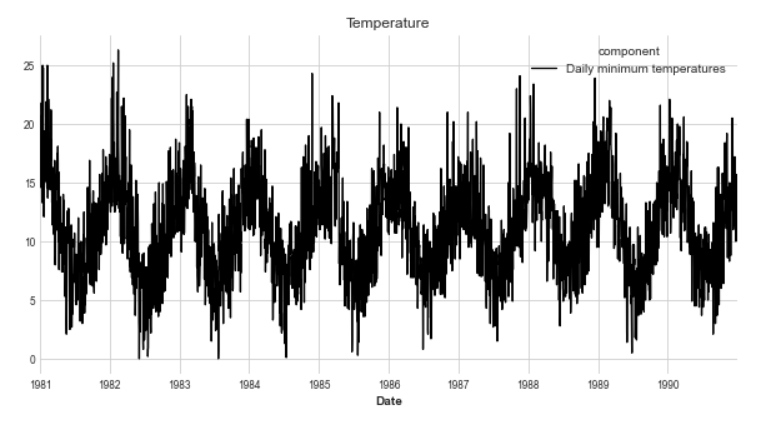
(6) Temperature Dataset
1981년부터 1980년까지 일간 온도 데이터 입니다.
# 데이터셋
from darts.datasets import TemperatureDataset
df_temp = TemperatureDataset().load().pd_dataframe()
df_temp
# 시각화
df_temp.plot(figsize=(10,5),title='Temperature')

2. 다변량 시계열(2개)
(1) GasRateCO2 Dataset
가스 비율과 CO2 비율에 대한 데이터 셋입니다.
# 데이터셋
from darts.datasets import GasRateCO2Dataset
df_co2 = GasRateCO2Dataset().load().pd_dataframe()
df_co2
# 시각화
df_co2.plot(figsize=(10,5), subplots=True)

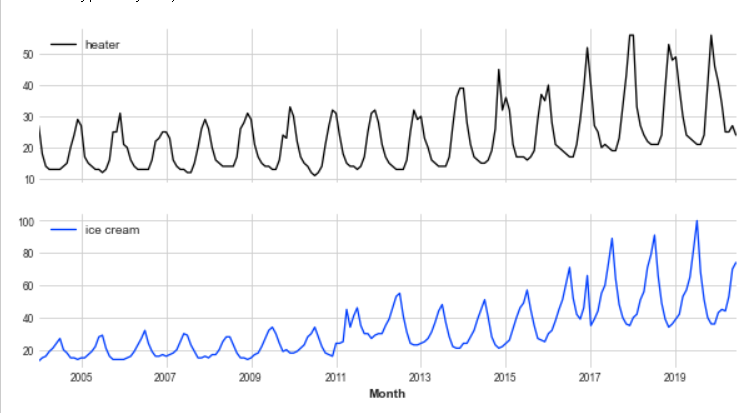
(2) IceCreamHeater Dataset
2004년부터 2020년까지 월간 히터 판매량과 아이스크림 판매량 데이터 입니다.
# 데이터셋
from darts.datasets import IceCreamHeaterDataset
df_ice = IceCreamHeaterDataset().load().pd_dataframe()
df_ice
# 시각화
df_ice.plot(figsize=(10,5), subplots=True)
3. 다변량 시계열
(1) ETTh1 Dataset
2016년 7월부터 2018년 7월까지 전기 트랜스포머(Electricity Transformer) 1곳에서의 데이터 입니다.
ETT 시리즈 데이터들은 Informer 논문에 쓰였습니다.
- date: The recorded date
- HUFL: High UseFul Load
- HULL: High UseLess Load
- MUFL: Medium UseFul Load
- MULL: Medium UseLess Load
- LUFL: Low UseFul Load
- LULL: Low UseLess Load
- OT: Oil Temperature (Target)
각 컬럼들에 대한 설명인데 공학도가 아니라서 정확한 의미는 잘 모르겠네요
# 데이터셋
from darts.datasets import ETTh1Dataset
df_ett1 = ETTh1Dataset().load().pd_dataframe()
df_ett1
# 시각화
df_ett1.plot(figsize=(10,5), subplots=True)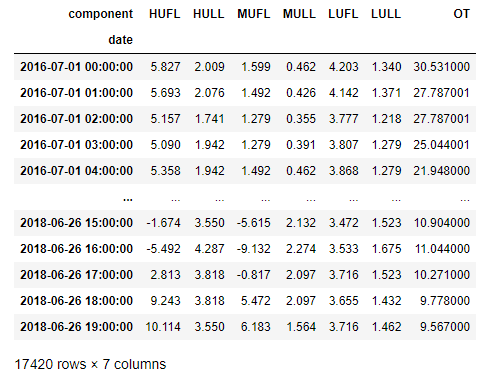

(2) Electiricity Dataset
한 가정 370곳에서 15분마다 전기 사용량을 측정한 데이터입니다.
데이터 행이 14만개, 컬럼이 370개인 매우매우 큰 다변량 데이터셋입니다.
저 같은 경우 데이터를 부르는데만 5분 이상 걸렸습니다.. 간단하게 분석할 거 아니면 다른 데이터셋을 사용하는 게 나을 수도 있을 것 같습니다.
# 데이터셋
from darts.datasets import ElectricityDataset
df_elec = ElectricityDataset().load().pd_dataframe()
df_elec.head()

다 그리기엔 너무 오래걸려서 10000행부터 20000행까지 시각화 했습니다.
# 시각화
df_ett1.plot(figsize=(10,5), subplots=True)
df_elec.iloc[10000:20000,:].plot(figsize=(10,5))
(3) Energy Dataset
시간별 여러가지 에너지 연료 소비량과 마지막컬럼에 전기 가격이 있는 데이터입니다.
컬럼이 많아서 5개정도만 시각화를 해보았습니다.
# 데이터셋
from darts.datasets import EnergyDataset
df_energy = EnergyDataset().load().pd_dataframe()
df_energy
# 시각화
df_energy.iloc[:,[0,1,3,4,-1]].plot(figsize=(10,5),subplots=True, title='Energy Dataset')

이외에도 몇가지 데이터셋들이 더 있습니다.
잘 참고하셔서 원하는 시계열 데이터로 분석에 사용하면 좋을 것 같습니다.
감사합니다.
출처: https://unit8co.github.io/darts/generated_api/darts.datasets.html
'데이터분석' 카테고리의 다른 글
| 시계열 평가지표(Forecasting Metrics) 정리 (0) | 2022.12.31 |
|---|---|
| [시계열 시각화] plotly를 통한 시계열 시각화 (0) | 2022.12.29 |
| [시계열 시각화] seaborn으로 시계열데이터 그려보기 (0) | 2022.12.28 |
| [시계열 데이터수집] 크롤링 다음페이지 넘기기 (0) | 2022.12.27 |