예전에 프로젝트를 하다가 전염병 관련 데이터를 모았던 일이 있습니다.
url 이 변하지 않아 selenium을 써야 했고 직접 한페이지 한페이지 넘기면서 데이터를 가져왔어야 했습니다.
다음페이지 버튼을 클릭해가며 끝까지 크롤링하는 부분이 생각보다 쉽지 않아 정리해보려 합니다.
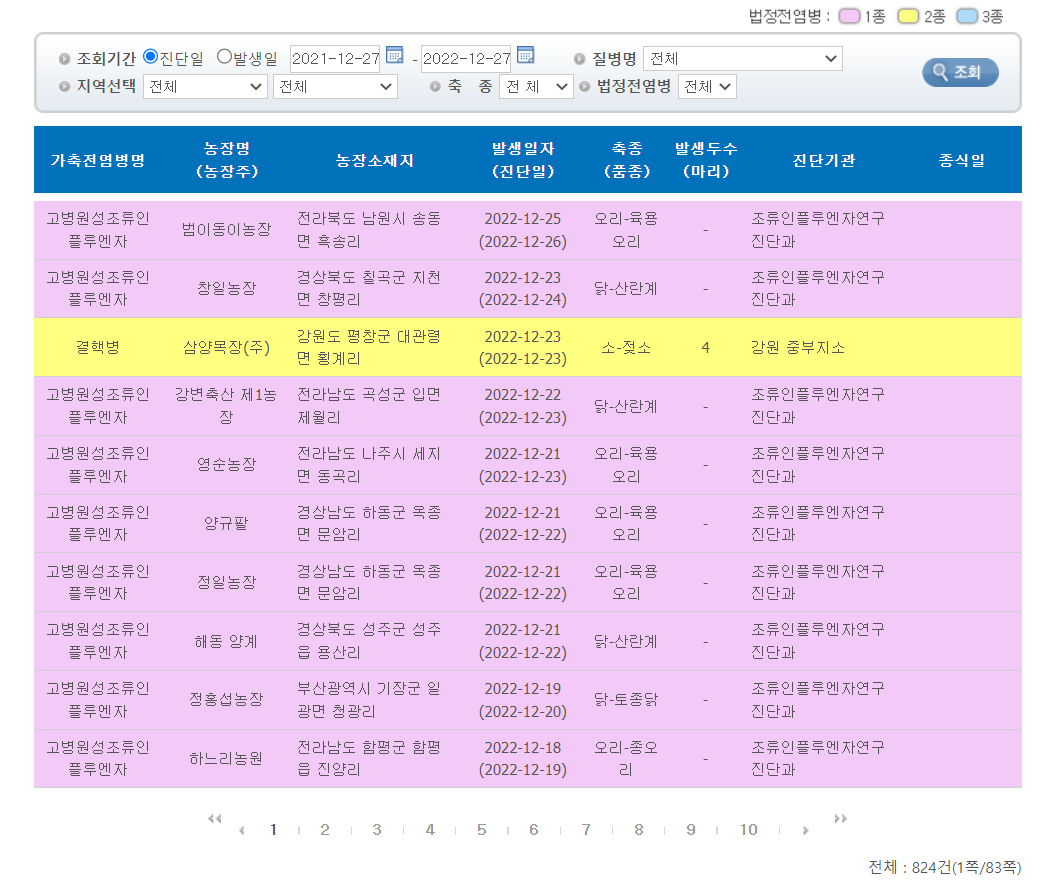
가져왔던 페이지는 국가가축방역통합시스템이고 가축전염병이 발생했던 날짜와 장소를 나타낸 데이터입니다.
https://home.kahis.go.kr/home/lkntscrinfo/selectLkntsOccrrncList.do
국가가축방역통합시스템
> 가축전염병 발생정보 > 국내현황 > 법정가축전염병 발생현황 법정가축전염병 발생현황
home.kahis.go.kr
크롤링을 하기 위해 셀레늄 드라이버를 부르고
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
options = webdriver.ChromeOptions()
# options.add_argument("headless")
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options = options, service=Service(ChromeDriverManager().install()))
driver.set_window_size(1500, 3000)
driver = webdriver.Chrome()
드라이버에 홈페이지 주소를 넣어주고 원하는 날짜, 전염병이름을 골라줍니다.
저는 1990년도부터 2021년까지 조류인플루엔자를 골랐습니다.
url = 'https://home.kahis.go.kr/home/lkntscrinfo/selectLkntsOccrrncList.do'
driver.get(url)
# 시작날짜 클릭
start_box = driver.find_element(By.CSS_SELECTOR,'#occrFromDtId')
# 시작날짜입력칸 클릭
start_box.click()
# 시작날짜입력
start_box.send_keys('19900101')
# 마지막 날짜 클릭
end_box = driver.find_element(By.CSS_SELECTOR,'#occrToDtId')
end_box.click()
# 마지막 날짜 입력
end_box.send_keys('20211231')
# 질병명 : '구제역' 고르기
elem = driver.find_element(By.CSS_SELECTOR,'#dissCl > option:nth-child(4)').click()
time.sleep(0.5)
# 조회 클릭
elem = driver.find_element(By.CSS_SELECTOR,'#btnSearch').click()
이 상태에서 현재페이지(1페이지) 정보를 가져오고 page_number들이 모인 리스트를
page_bar로 받아 크롤링을 진행해주면
page_bar = driver.find_elements(By.CSS_SELECTOR,'#homeLkntscrinfoVO > table:nth-child(7) > tbody > \
tr:nth-child(2) > td > table > tbody > tr > td > a')
page = 10
df = pd.DataFrame()
for p in range(1,page+1):
for button in page_bar:
if button.text == str(p):
button.click()
break
html = driver.page_source
df = pd.concat([df,pd.read_html(html)[8]])
if p % 10 == 0:
driver.find_elements(By.CSS_SELECTOR,'#homeLkntscrinfoVO > table:nth-child(7) > tbody > \
tr:nth-child(2) > td > table > tbody > tr > td > a')[11].click()
df
2페이지가 넘어가면서 오류가 나는 것을 볼 수 있습니다. 오류를 보니 클릭할 객체가 없어서 나는 오류입니다.
확인해보면 button.click()을 하고 다시 클릭을 했을때 오류가 나는 걸 알 수 있습니다.

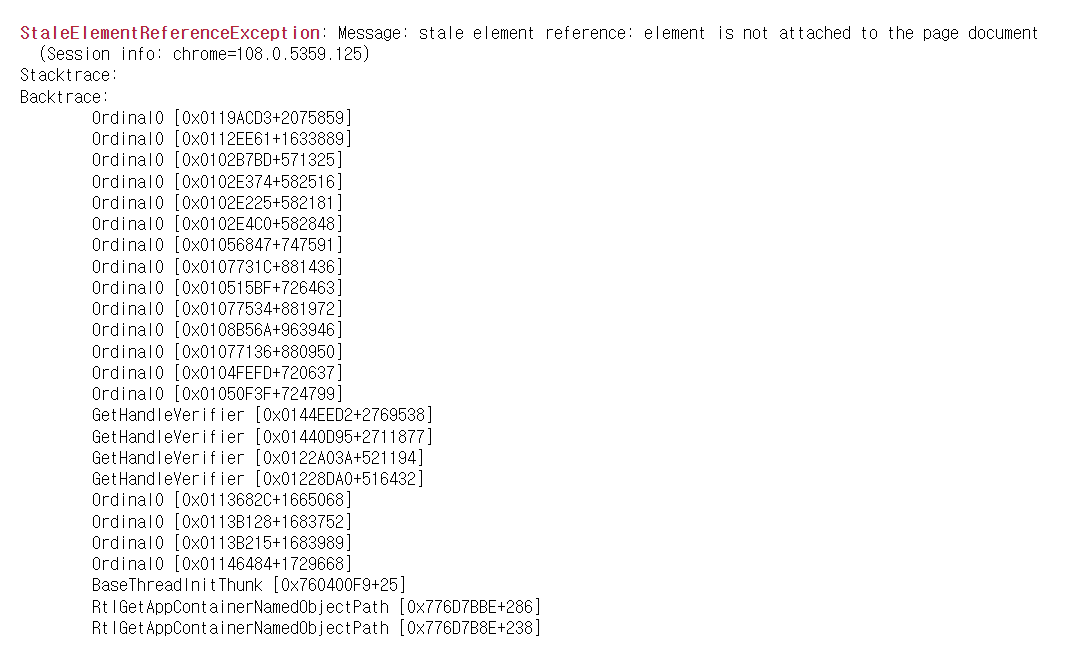
이런 이유는 페이지가 넘어갈 때 마다 page_bar에 해당하는 정보가 달라지기 때문입니다.
그래서 button.click() 을 하기 전에 page_bar를 다시 지정해 주어야 이 문제를 해결할 수 있습니다.
밖에 있던 page_bar 지정 부분을 for문 안쪽으로 넣어주면 해결됩니다.
page = 10
df = pd.DataFrame()
for p in range(1,page+1): # 원하는 페이지까지 반복문
# for문 안에 page_bar를 넣어주어 매번 지정
page_bar = driver.find_elements(By.CSS_SELECTOR,'#homeLkntscrinfoVO > table:nth-child(7) > tbody > \
tr:nth-child(2) > td > table > tbody > tr > td > a')
for button in page_bar:
if button.text == str(p):
button.click()
break
html = driver.page_source
df = pd.concat([df,pd.read_html(html)[8]])
if p % 10 == 0: # 10의 배수일때 다음10페이지 버튼 클릭
driver.find_elements(By.CSS_SELECTOR,'#homeLkntscrinfoVO > table:nth-child(7) > tbody > \
tr:nth-child(2) > td > table > tbody > tr > td > a')[11].click()
df

오류가 안나고 크롤링이 잘 되는 걸 볼 수 있습니다!
도움이 되셨으면 좋겠습니다~ 감사합니다
'데이터분석' 카테고리의 다른 글
| 시계열 평가지표(Forecasting Metrics) 정리 (0) | 2022.12.31 |
|---|---|
| [시계열 시각화] plotly를 통한 시계열 시각화 (0) | 2022.12.29 |
| [시계열 시각화] seaborn으로 시계열데이터 그려보기 (0) | 2022.12.28 |
| [시계열 데이터수집] darts 모듈 데이터셋 살펴보기 (0) | 2022.12.26 |